偌依项目分页查询
代码分析
参考若依系统模块中用户相关数据接口
/**
* 获取用户列表
*/
@PreAuthorize("@ss.hasPermi('system:user:list')")
@GetMapping("/list")
public TableDataInfo list(SysUser user)
{
startPage();
List<SysUser> list = userService.selectUserList(user);
return getDataTable(list);
}startPage()方法
/**
* 设置请求分页数据
*/
public static void startPage() {
PageDomain pageDomain = TableSupport.buildPageRequest();
Integer pageNum = pageDomain.getPageNum();
Integer pageSize = pageDomain.getPageSize();
String orderBy = SqlUtil.escapeOrderBySql(pageDomain.getOrderBy());
Boolean reasonable = pageDomain.getReasonable();
PageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable);
}TableSupport.buildPageRequest()方法:从请求头中获取对应的参数信息
/**
* 封装分页对象
*/
public static PageDomain buildPageRequest() {
PageDomain pageDomain = new PageDomain();
pageDomain.setPageNum(Convert.toInt(ServletUtils.getParameter(PAGE_NUM), 1));
pageDomain.setPageSize(Convert.toInt(ServletUtils.getParameter(PAGE_SIZE), 10));
pageDomain.setOrderByColumn(ServletUtils.getParameter(ORDER_BY_COLUMN));
pageDomain.setIsAsc(ServletUtils.getParameter(IS_ASC));
pageDomain.setReasonable(ServletUtils.getParameterToBool(REASONABLE));
return pageDomain;
}这段代码是一个用于设置请求分页数据的方法:
TableSupport.buildPageRequest(): 从TableSupport类中调用buildPageRequest方法,该方法用于构建分页请求的参数。这可能包括当前页码(pageNum)、每页显示的记录数(pageSize)、排序字段(orderBy)等信息。
PageHelper.startPage(pageNum, pageSize, orderBy): 使用MyBatis框架的PageHelper工具类的startPage方法来启动分页。该方法用传入的页码(pageNum)、每页显示的记录数(pageSize)和排序字段(orderBy)来配置分页信息。
setReasonable(reasonable): 设置分页插件的"reasonable"属性,这是PageHelper插件的一个配置项。当设置为true时,如果页码超出范围,则会自动调整为第一页或最后一页;当设置为false时,如果页码超出范围,则不进行调整。
这段代码的目的是为了简化在MyBatis中进行分页查询的操作。通过调用这个方法,可以方便地从请求中获取分页相关的参数,并配置PageHelper,使得分页能够在数据库查询中生效。这种做法可以提高代码的可维护性和可读性。
getDataTable()对象
protected TableDataInfo getDataTable(List<?> list)
{
TableDataInfo rspData = new TableDataInfo();
rspData.setCode(HttpStatus.SUCCESS);
rspData.setMsg("查询成功");
rspData.setRows(list);
rspData.setTotal(new PageInfo(list).getTotal());
return rspData;
}问题一:PageHelper 如何知道总共多少条数据?
当你使用 PageHelper 分页时,它实际上执行了 两条 SQL 语句:
- 第一条:获取总记录数(count(*)),PageHelper 会自动拦截你的原始查询 SQL,把它转换成一条用于统计总行数的 SQL 语句。
SELECT COUNT(*) FROM your_table WHERE ...- 第二条:带分页的查询(LIMIT)
SELECT * FROM your_table WHERE ... ORDER BY xxx LIMIT ?, ?这两条 SQL 是自动执行的,你只写一次查询代码,PageHelper 会“帮你做掉这些”。
PageHelper 源码解析
实现原理
PageHelper是利用Mybatis拦截器实现分页的,他的基本原理是:
1、应用层在需要分页的查询执行前,设置分页参数。
2、使用Mybatis的Executor拦截器拦截所有的query请求。
3、在拦截器中检查当前请求是否设置了分页参数,没有设置分页参数则执行原查询返回所有结果。
4、如果当前查询设置了分页参数,则执行分页查询:根据数据库类型改造当前的查询sql语句,增加获取当前页数据的sql参数,比如对于mysql数据库,在sql语句中增加limit语句。
执行改造后的分页查询,获取数据返回。ThreadLocal在PageHelper中的应用
/**
* PageHelper 启动分页的静态方法。
*
* @param pageNum 当前页(从 1 开始)
* @param pageSize 每页条数
* @param count 是否统计总记录数(决定是否生成 SELECT COUNT(*) ... 语句)
* @param reasonable 是否开启 “合理化” 分页(小于 1 自动转 1,大于最大页自动转最后一页)
* @param pageSizeZero pageSize=0 时是否查询全部数据(返回 list,但 pageSize=0 不进行分页)
* @param <E> 返回的 Page 对象内部数据列表的元素类型
* @return 已初始化并放入 ThreadLocal 的 Page 对象
*/
public static <E> Page<E> startPage(int pageNum,
int pageSize,
boolean count,
Boolean reasonable,
Boolean pageSizeZero) {
// ① 创建 Page 对象:保存当前分页请求的所有关键信息
Page<E> page = new Page<>(pageNum, pageSize, count);
// ② 设置“合理化分页”开关:防止 pageNum 异常
page.setReasonable(reasonable);
// ③ 设置 pageSizeZero 行为:pageSize 传 0 时是否返回全部记录
page.setPageSizeZero(pageSizeZero);
// ④ 获取当前线程的旧 Page(如果代码里已经先 startPage(orderByOnly=true) 只为了排序)
Page<E> oldPage = getLocalPage();
/*
* ⑤ 若旧 Page 仅包含 orderBy(orderByOnly=true),
* 那么继承它的 orderBy 字段,保持排序一致。
* 典型场景:先调用 PageHelper.orderBy("xxx"),再调用 startPage(...)
*/
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
// ⑥ 将新创建的 Page 对象放入 ThreadLocal
setLocalPage(page);
// ⑦ 返回 Page 对象给调用方(大多数时候调用方不会直接用,PageHelper 内部需要)
return page;
}| 步骤 | 作用 | 说明 |
|---|---|---|
| ① | 创建 Page | 保存页码、条数、是否统计 count 等 |
| ② | 合理化分页 | 防止页码超出范围或小于 1 |
| ③ | pageSizeZero | pageSize=0 时可一次查全部 |
| ④~⑤ | 继承排序 | 若之前单独设置了 orderBy,保证排序不丢失 |
| ⑥ | ThreadLocal | 核心:把分页信息塞进当前线程的 ThreadLocal,供 MyBatis 插件读取 |
| ⑦ | 返回 Page | 调用处可链式操作(少用);真正用的是插件内部 |
Page<E> oldPage = getLocalPage(); setLocalPage(page)方法都是看当前线程中的 ThreadLocal.ThreadLocalMap 中是否存在该 page 对象,若存在直接取出,若不存在则设置一个,以第一个为例继续深入
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();
/**
* 获取 Page 参数
* @return
*/
public static <T> Page<T> getLocalPage() {
return LOCAL_PAGE.get();
}
public T get() {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程中的ThreadLocalMap
ThreadLocalMap map = getMap(t);//ThreadLocal.ThreadLocalMap threadLocals = null;
if (map != null) {
//getEntry(ThreadLocal<?> key)源码在下边
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();//=> t.threadLocals = new ThreadLocalMap(this, firstValue);
}
private Entry getEntry(ThreadLocal<?> key) {
//通过hashCode与length位运算确定出一个索引值i,这个i就是被存储在table数组中的位置
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}PageHelper实际拦截SQL
Mybatis拦截器可以对下面4种对象进行拦截:
- Executor:mybatis的内部执行器,作为调度核心负责调用StatementHandler操作数据库,并把结果集通过ResultSetHandler进行自动映射
- StatementHandler: 封装了JDBC Statement操作,是sql语法的构建器,负责和数据库进行交互执行sql语句
- ParameterHandler:作为处理sql参数设置的对象,主要实现读取参数和对PreparedStatement的参数进行赋值
- ResultSetHandler:处理Statement执行完成后返回结果集的接口对象,mybatis通过它把ResultSet集合映射成实体对象
PageInterceptor :负责在 MyBatis 执行查询语句时自动拦截,并根据当前线程上下文(通过 PageMethod.getLocalPage() 获取)判断是否需要进行分页,自动执行 count 查询、构造分页语句,并返回分页后的结果。
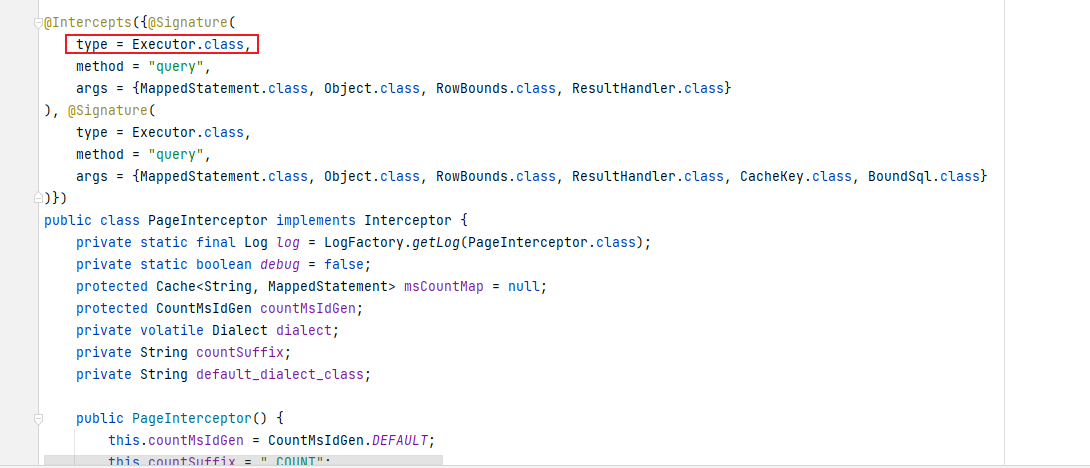
intercept: 在 MyBatis 执行 SQL 查询前插入分页逻辑,包括是否分页、是否统计总数、生成分页 SQL,并在查询后封装分页结果
public Object intercept(Invocation invocation) throws Throwable {
try {
// 1. 获取参数:MappedStatement、参数对象、RowBounds(分页参数)、ResultHandler
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget(); // 拦截的目标对象(Executor)
CacheKey cacheKey;
BoundSql boundSql;
// 2. 判断是 query 的哪种重载方法,获取 BoundSql 和 CacheKey
if (args.length == 4) {
boundSql = ms.getBoundSql(parameter); // 获取 SQL 和参数信息
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql); // 创建缓存 key
} else {
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
// 3. 确保方言对象已经初始化(根据数据库类型决定分页 SQL 的生成策略)
this.checkDialectExists();
// 4. 如果启用了 BoundSql 拦截器链,先处理原始 BoundSql(如数据权限、租户字段等修改)
if (this.dialect instanceof BoundSqlInterceptor.Chain) {
boundSql = ((BoundSqlInterceptor.Chain) this.dialect).doBoundSql(Type.ORIGINAL, boundSql, cacheKey);
}
List resultList;
// 5. 判断是否跳过分页处理
if (!this.dialect.skip(ms, parameter, rowBounds)) {
// 5.1 如果开启了 debug 模式,可以打印堆栈日志
this.debugStackTraceLog();
// 5.2 判断是否需要执行 count 查询(获取总条数)
if (this.dialect.beforeCount(ms, parameter, rowBounds)) {
// 5.2.1 执行 count 查询,内部构建 count SQL 并执行
Long count = this.count(executor, ms, parameter, rowBounds, null, boundSql);
// 5.2.2 如果 afterCount 返回 false,说明不再执行分页 SQL,直接返回空分页结果
if (!this.dialect.afterCount(count, parameter, rowBounds)) {
Object emptyPage = this.dialect.afterPage(new ArrayList(), parameter, rowBounds);
return emptyPage;
}
}
// 5.3 执行分页查询,返回结果列表(调用底层分页 SQL)
resultList = ExecutorUtil.pageQuery(this.dialect, executor, ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
// 6. 如果跳过分页,执行原始查询
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
// 7. 包装查询结果,构造 Page 对象或其他分页结构返回
Object pageResult = this.dialect.afterPage(resultList, parameter, rowBounds);
return pageResult;
} finally {
// 8. 无论是否分页,最后都会调用 dialect.afterAll() 进行清理或钩子操作
if (this.dialect != null) {
this.dialect.afterAll();
}
}
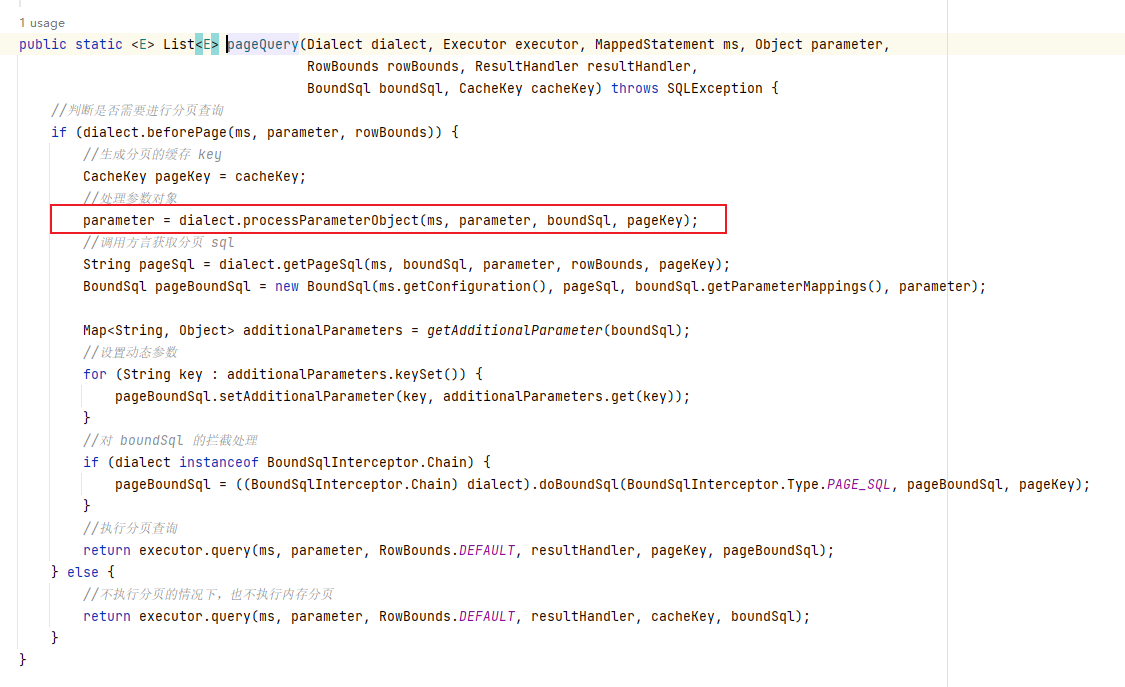
}ExecutorUtil.pageQuery 方法
// 主要代码
public static <E> List<E> pageQuery(Dialect dialect, Executor executor, MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql, CacheKey cacheKey) throws SQLException {
//判断是否需要进行分页查询
if (dialect.beforePage(ms, parameter, rowBounds)) {
//生成分页的缓存 key
CacheKey pageKey = cacheKey;
//处理参数对象
parameter = dialect.processParameterObject(ms, parameter, boundSql, pageKey);
...
}
}
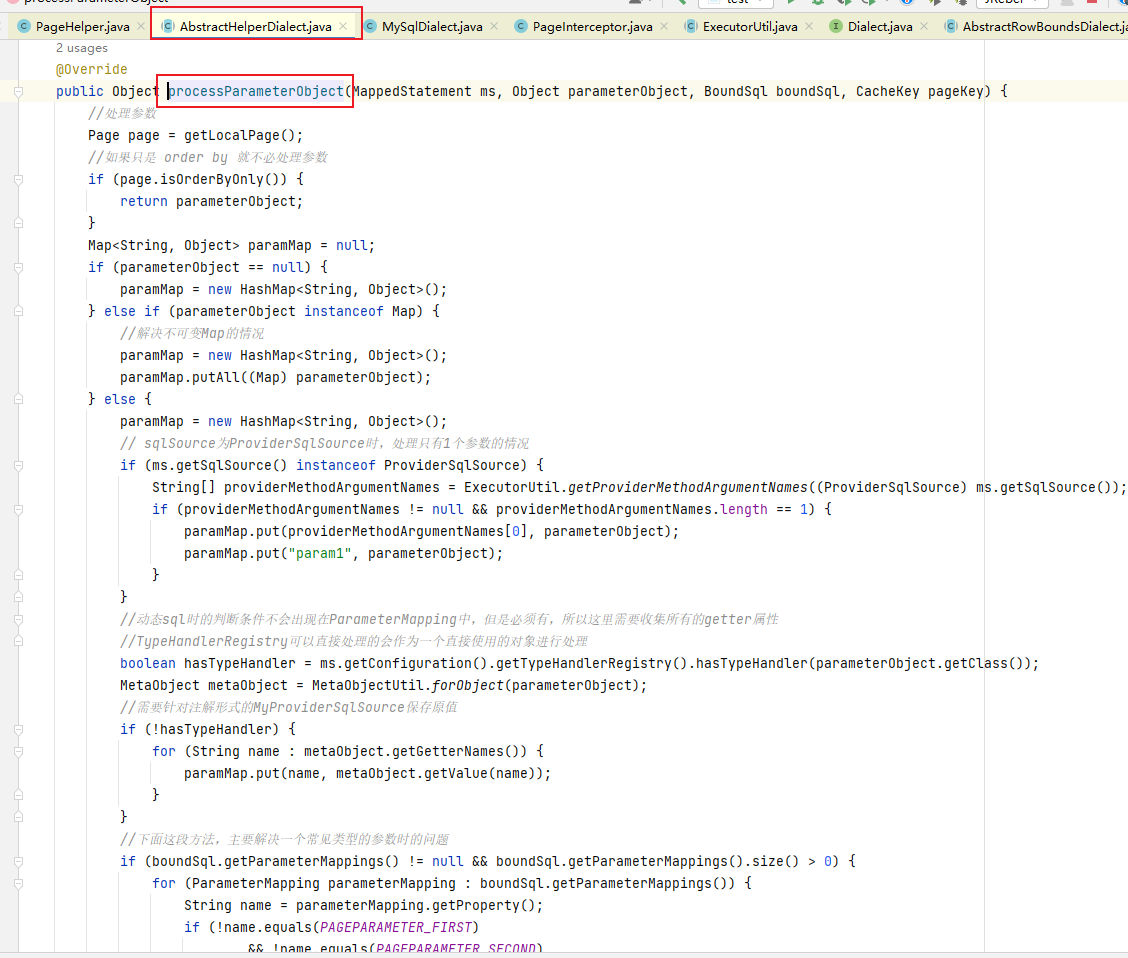
processParameterObject方法
// 主要代码
@Override
public Object processParameterObject(MappedStatement ms, Object parameterObject, BoundSql boundSql, CacheKey pageKey) {
...
return processPageParameter(ms, paramMap, page, boundSql, pageKey);
}
processPageParameter方法 :将分页数据放进参数中,然后执行分页的逻辑
@Override
public Object processPageParameter(MappedStatement ms, Map<String, Object> paramMap, Page page, BoundSql boundSql, CacheKey pageKey) {
// 设置分页参数:起始行(startRow)和页大小(pageSize),用于拼接分页 SQL 的参数
paramMap.put(PAGEPARAMETER_FIRST, page.getStartRow());
paramMap.put(PAGEPARAMETER_SECOND, page.getPageSize());
// 将分页参数添加进 CacheKey,确保不同页的缓存键不同,避免使用错误缓存结果
pageKey.update(page.getStartRow());
pageKey.update(page.getPageSize());
// 如果原 BoundSql 中已有参数映射信息,则复制一份并添加分页参数的映射信息
if (boundSql.getParameterMappings() != null) {
// 拷贝原始参数映射列表
List<ParameterMapping> newParameterMappings = new ArrayList<ParameterMapping>(boundSql.getParameterMappings());
// 根据 startRow 是否为 0 判断是否需要添加 offset 参数的映射(仅 LIMIT 或 LIMIT offset, size)
if (page.getStartRow() == 0) {
// 只添加 pageSize 的参数映射(LIMIT ?)
newParameterMappings.add(new ParameterMapping.Builder(ms.getConfiguration(), PAGEPARAMETER_SECOND, int.class).build());
} else {
// 同时添加 offset 和 pageSize 的参数映射(LIMIT ?, ?)
newParameterMappings.add(new ParameterMapping.Builder(ms.getConfiguration(), PAGEPARAMETER_FIRST, long.class).build());
newParameterMappings.add(new ParameterMapping.Builder(ms.getConfiguration(), PAGEPARAMETER_SECOND, int.class).build());
}
// 使用 MetaObject 反射工具设置新的 parameterMappings,更新 BoundSql 参数映射信息
MetaObject metaObject = MetaObjectUtil.forObject(boundSql);
metaObject.setValue("parameterMappings", newParameterMappings);
}
// 返回处理后的参数 map
return paramMap;
}